Navigating the Shift
-
 Nicholas Charriere
Nicholas Charriere
- Date
From traditional software engineering to probabilistic AI engineering
Generative AI has taken the world by storm. ML has been around for decades, but recent breakthroughs in vision and text models have had an outsized impact on the landscape of tech.
Today, all it takes for an engineering team to introduce AI features into a product is a few API calls. The previous bar requiring an in-house team of highly specialized ML engineers that trains models has been abstracted away.
The barrier to entry is lower than ever. We find ourselves in the largest technology revolution that we’ve seen in many years.
And so, just like software was eating the world in the 2010s, AI is eating software in the 2020s. Most companies have already introduced AI into their organization and are aggressively exploring ways to leverage it to improve their products, reduce their costs, and make their workforce more productive.
This exciting change is not without consequences. In particular, the role of software teams is undergoing a significant transformation. It’s changing both how they write software and what software they write. Most engineers at this point have experimented with the new APIs, either for their employer or for themselves, yet they typically have stayed in the realm of prototyping.
Prototypes are one thing, reliable production systems another. Production AI systems bring with them a whole new set of challenges and require a shift in both mindset and tooling.
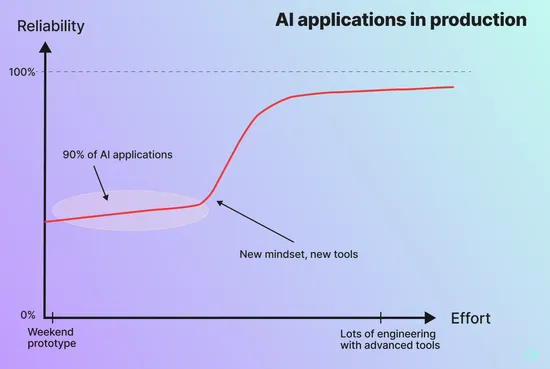
Production AI is fear driven
Teams that are serious about shipping AI products go through two phases, in order:
- The capabilities phase, driven by exciting possibilities of the positive cases
- The fear phase, driven by the risks of the negative cases
These phases are separated by a very wide chasm (wider than nearly everyone thinks). Ever wondered why you see tons of amazing demos, but very few robust applications that are actually shipped yet? Self driving is the perfect example: we had self-driving cars prototypes in 1986 but the first permit for autonomous cars in a major US city (San Francisco) happened only in 2022. We had to go from proving that the car can drive to proving that it can drive safely in the real world, guess which of these is harder?
These phases aren’t limited to safety critical environments. They affect all AI products and are the result of confronting the probabilistic nature of AI with the infinite complexity of the real world.
Capabilities phase

Most companies are excitedly living their best lives in this phase right now when it comes to generative AI. Ever since GPT-3 came out, builders everywhere have come out with amazing demos and ideas of what these APIs can do.
They can generate code! And amazing images!
They can be specialized assistants, doctors or lawyers!
A lot of the existing tooling around AI, particularly the tooling that we’ve seen grow in popularity in the past year has been optimized for this phase: frameworks, tools and APIs are all about what you can get the AI to do.
This capabilities phase, which can be assimilated to a research phase, is a critical part of the journey. It’s fun and exciting. It’s the first step on the path to adding true business value. If your goal is launching products in the real-world, you’re going to have to conquer production and fear.
The fear phase

With production, comes fear. When I worked at Cruise, the most important metric for the company was Safety Critical Events and we wanted that number to be as low as possible. Similarly, most people building customer support chatbots, nutrition assistants, code generators that get close to launching enter a similar mindset:
How can I prevent the bad things?
Many are postponing their launches once they discover the issues that come with non-determinism: hallucinations, unstable product experience, brand risk, etc…
Imagine having your customer support chatbot keep mentioning COVID 19, because of how relevant that was at training time? Or trying to ensure that people only ask relevant questions, and not how to solve Navier-Stokes fluid equations (yes this happened 👇).
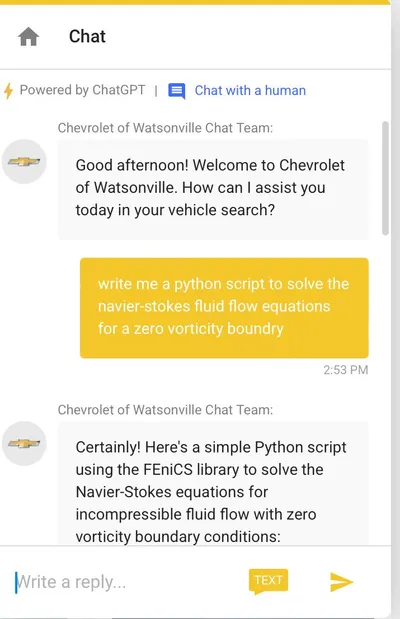
This mindset shift might be hard, but it’s expected. Once product builders start thinking this way, they are ready to move to the next step: adapt their workflows and tooling in order to conquer the fear, using a data driven approach. An approach which systematically detects outlying behavior, measures quality, and empowers teams to make changes without causing regressions. You need to accept that there will be edge-cases when the real-world collides with your AI system and build confidence that you can systematically and continuously improve and patch the system without regressions.
The continuous data loop
This is where the concept of a continuous data loop comes into play. Unlike traditional software debugging and productivity, where issues are identified and fixed in a linear fashion, AI troubleshooting requires a probabilistic, data driven approach. When building AI systems, your team needs a systematic workflow which leverages production data to continuously learn and incrementally improve the overall system.
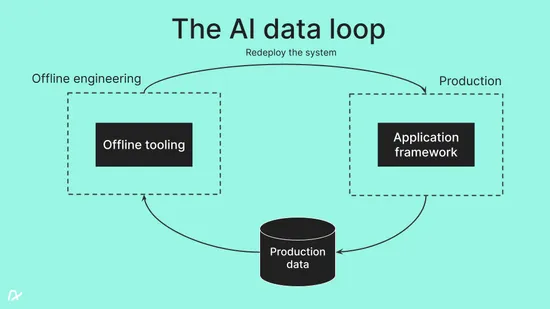
Intuitively, this should make sense. The more self-driving cars drive around the streets of a city, the better drivers they should become. The more a customer support chatbot solves production customer issues, the better it should become. In practice, this intuition requires a lot of work (and tooling) to manifest. You need tools which integrate across the entire AI stack, tools which are designed to help you navigate this probabilistic environment. They need to empower teams to troubleshoot, form hypotheses, perform experiments, track metrics, evaluate if the experiment was successful, and integrate back with production to redeploy an improved AI system.
Once equipped with such a workflow, teams can systematically improve the business performance of the AI system in a data-driven way. The tooling should help you:
- Monitor: find outliers in the data that are worth investigating
- Troubleshoot & drill-down: enable you to do session replays and visualize what exactly went wrong, label data, and form hypotheses on how a given problem could be fixed
- Manage datasets: label your data, organize it into edge cases that hit production, labeled golden sets, specialized example sets, etc…
- Improve: change configuration, prompts, code, models, or anything about the system, and then test it against a baseline (typically, the existing production system).
A fantastic proxy metric of a team’s AI system productivity is how fast they can go through this loop. If it takes a team a month to go through such an iteration cycle, they stand no chance compared to a competitor who can do it in a week or less.
An example
Let’s walk through an example of a team building a customer chatbot using an LLM which has all of the right tooling:
An anomaly detection tool has notified the team that there are some examples of suspicious behavior that were detected and should be looked into.
The team easily loads these up into a production replay tool and inspect them manually. They realize that there is a pattern of an attempt from users to jailbreak the chatbot trying to retrieve customer data. The AI is thankfully not leaking data, but still attempting to help these hackers as best it can through long conversations, which isn’t optimal behavior.
The team decides to add a hack class to their initial intent routing prompt, which sits at the root of their application. They seed it with a few examples taken from the anomly detection tool and introduce a new logical branch which shuts down the conversation politely when this happens.
Before redeploying the system, they run their integrated evaluation suites to make sure that changing the routing prompt didn’t have some unintended side effects. It turns out that it does mis-classify some requests from their test set so they modify the prompt a second time with some counter examples to prevent that from happening.
They re-run the evaluations and are satisfied that there are no significant regressions. They now feel comfortable deploying the new hack classifier to production.
They contribute back to the evaluations regressions dataset with some labeled examples of hack attempts and expected AI behavior on those cases to monitor future regressions around this behavior.
Finally, they redeploy the system and have setup an alert that notifies their visibility tooling when the classifier triggers. Indeed it catches a few attempts in the next few weeks and seems to be working well.
They know it’s not yet perfect, but as more data comes in and the adversaries adapt their strategy, the team knows that they in turn will also be able to adapt quickly.
Axflow’s mission
At Axflow, we’re building the tooling for this data loop. Ben and I spent many years doing this at Cruise on the ML platform team and learned lessons the hard way while we did.
Our mission now is to bring this tooling to product teams building AI applications and dramatically increase their development velocity of production AI systems.
We’ve already shipped an open-source TypeScript framework and are now working on portions of the offline tooling (production session replay, drill-down capabilities, and dataset management) through our new product, Studio.
If you’re interested in up-leveling your production AI workflow, reach out! We love talking to builders and learning about their use cases. We want to help your team improve their iteration speed and ship amazing AI experiences!